
深度揭秘(验证码识别程序下载)验证码识别平台是干嘛的,工具应用:利用Tesseract-OCR实现验证码识别,tesseract ocr java,
实验简介
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。OCR技术非常专业,一般多是印刷、打印行业的从业人员使用,可以快速的将纸质资料转换为电子资料。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。Tesseract目前已作为开源项目发布在Google Project,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。
验证码是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式。由于验证码可以由计算机生成并评判,但是必须只有人类才能解答,所以回答出问题的用户就可以被认为是人类。
但是在我们的测试开发过程中,难免会存在需要使用到验证码的时候,所以本实验则主要利用Java通过封装Tesseract-OCR命令和调用Tess4J两种方式,实现验证码的识别。
实验目的
(1)理解验证码的工作原理和应用场景。
(2)熟练使用Tesseract-OCR的命令完成对一张图片验证码的识别。
(3)使用Java调用Tesseract-OCR的命令完全图片的验证码自动化处理。
(4)使用Tess4J完成验证码的识别处理。
(5)利用Java通过封装完成对一个站点的验证码自动化识别处理。
实验流程
关于验证码验证码是防止程序对一个站点发起自动化请求的很重要的一种手段,特别是实现登录的过程,向站点提交数据的过程等,我们必须有一种机制防止自动化程序向网站发起请求。
所谓道高一尺,魔高一丈。验证码和破解验证码就在双方的拉锯战中越来越厉害,越来越难以破解。目前的验证码通常的种类及特点如下:
(1)最基础的英文验证码:纯粹的英文与数字组合,白色背景,这是最容易实现OCR识别的验证码。
(2)字体变形的英文验证码:可以通过简单的机器学习实现对英文与数字的识别,准确率较高。
(3)加上扰乱背景线条的验证码:可以通过程序去除干扰线,准确率较高。
(4)中文验证码:中文由于字体多样,形状多变,数量组合众多,实现起来难度较大,准确率不高。
(5)中文字体变形验证码:准确率更低。
(6)中英文混合验证码:非常考验OCR程序的判断能力,基本上识别起来非常有难度。
(7)提问式验证码:这是需要OCR结合人工智能才能实现,目前基本上无法识别。
(8)GIF动态图验证码:由于GIF图片是动态图,无法定位哪一帧是验证码,所以难度很大。
(9)划动式验证码:虽然程序可以模拟人的操作,但是具体拖动到哪个位置很难处理。
(10)视频验证码:目前OCR识别还未实现。
(11)手机验证码:手机验证码实现自动化是很容易的,但是手机号码不那么容易获得。
(12)印象验证码:目前无解。

我们可以看到上述形形色色的验证码,目前用纯粹的技术手段是很难处理验证码问题的。所以,也有很多人看到这件事情的价值,专门雇佣大量人员帮助客户实现人工打码,把它变成了一门生意。
2. Tesseract-OCR基础使用
(1)下载Tesseract-OCR,官方网站为:https://sourceforge.net/projects/tesseract-ocr-alt/files/ 。
(2)安装Tesseract-OCR,建议安装在不包含空格的路径里,不要安装在默认的Program Files文件夹。比如笔者的安装路径为:C:\Tools\Tesseract-OCR 。
(3)在环境变量中添加TESSDATA_PREFIX变量,值为OCR安装目录:C:\Tools\Tesseract-OCR。
(4)准备一些英文和数字的验证码,可以带背景干扰线。比如将此验证码图片保存在D:\Other\VerifyCode目录中。
(5)打开CMD命令行程序,执行如下命令,即可将识别到的验证码内容输出到一个.txt文本文件中。
我们来看看具体的运行效果:
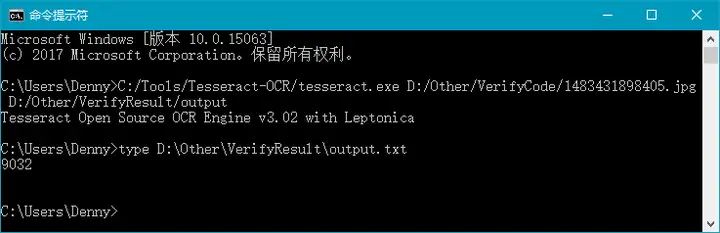
我们可以看到,tesseract.exe是执行识别的主命令,后面跟的第一个参数为指定验证码图片所在的路径和文件名,第二个参数为识别结果的输出路径,此处指输出到文件D:/Other/VerifyResult/output.txt中,但是我们不需要在后面特别添加.txt后缀。
(6)如果我们想实现中文的验证,则需要下载中文训练字库文件,文件名为:chi_sim.traineddata,将该文件下载到电脑后,保存至C:\Tools\Tesseract-OCR\tessdata文件夹中。
(7)识别中文验证码时只需要在正常命令后面添加“ –l chi_sim”指定训练字库文件即可。
事实上,Tesseract-OCR默认使用的是英文字库,字库名称为eng.traineddata,我们也可以下载更多的字库来对其识别的准确率进行扩展。
3. 使用Java调用Tesseract-OCR命令完成识别
由于Tesseract-OCR并没有专门提供编程接口,所以我们不能直接通过引入Jar包的方式来进行调用。但是由于Tesseract-OCR是通过命令来完成识别的,所以我们就可以让Java去执行这段命令。并且识别到的结果也是输出到文件中,所以我们自然可以利用Java去读取这段文本内容,进而获得识别到的结果。下面我们来看看具体的实现过程。
(1)Java执行Windows命令主要通过Runtime对象来完成。所以我们自然会需要调用该对象执行命令。
(2)由于命令当中有三个核心参数,验证码路径,输出路径,字库名称,所以我们需要使用编程的方式对该参数进行拼接,最后变成一个字符串完成命令的发送和执行。
(3)我们的验证码图片的路径和名称不一样,所以我们的识别程序应该将其参数化。同时,也可根据自身需要对三个核心参数均使用形式参数的方式在调用该识别程序时传递进来。
(4)我们需要判断命令是否执行成功,如果没有执行成功,则提示出错信息,否则,读取该输出文件的内容,并将其结果返回给调用该程序的地方。
核心代码实现如下,读者可根据自身需要进行修改和优化。
4. 如何实现站点验证码的自动识别
事实上,上述过程中我们已经将验证码的识别设置了自动化处理了。但是是基本文件的图片,而通常情况下,我们要识别的验证码是基于网络的,所以我们需要再提前完成一件事情,利用Java代码完成验证码的自动下载和保存,代码如下:
5. 针对某个具体的站点实现自动化操作
前面的很多实验我们已经了解了如何利用Java的协议通信API对象实现请求的发送和接收,以及处理HTTP的无状态特性等。那么,现在,我们不妨综合利用前面的知识,来试着完整地完成一个有验证码的操作。在此,笔者不提供代码实现,而是给大家提供一个关键思路:
(1)利用协议分析工具,分析验证码图片的生成机制,确认是否可以将该验证码下载到本地。
(2)获取到一个有效的验证码图片的地址,如果图片地址是动态生成的,则查看是否有规律可循环。
(3)利用download()方法实现对该图片的下载。
(4)利用recognizeText()方法识别到该图片的内容。
(5)利用sendPost()方法实现请求的发送和响应的处理。
6. 利用Java代码去除干扰线
这是笔者在网络上收获的一段非常有价值的代码,在些对热心奉献的网友表示感谢。这段代码通过对图片进行像素级的处理,将一些颜色偏淡一点的背景杂色干扰线等进行了过滤,使得识别率变得更加准确。笔者亲测,效果不错。
网址为: http://blog.csdn.net/lmj623565791/article/details/23960391/
7. 如果验证码搞不定怎么办
通常情况下,我们要去识别验证码不一定是为了测试我们自己的项目,而是为了去干一些坏事。所以,这是大家一定要慎重的地方。我们在自己的测试项目中,如果真的出现验证码根本无法识别,而我们又需要绕开验证码,应该怎么办呢?方法很简单,让研发团队协助我们开发一个万能的验证码,或者在测试环境中取消验证码就好了。
思考练习
(1)如果自己正在测试的项目遇到复杂的验证码,应该如何处理。
(2)了解一下关于图像处理和人工智能方面的知识。
本文系作者 @河马 原创发布在河马博客站点。未经许可,禁止转载。

暂无评论数据